I'm a software and data engineer finishing my M.S. in Computer Science at NC State. I like building things with real constraints: pipelines that process millions of records, applications that load fast, systems other engineers can trust and extend.
Most of my recent work has been in data infrastructure. I built an observability library at Perdis AI that brought dataset ingestion from 10 minutes to 10 seconds, shipped SCD Type 2 pipelines over millions of records with Delta Lake, and led backend development on a SAS-sponsored senior design project governing 5,000+ enterprise data entries. I hold four Databricks certifications and spend most of my time in PySpark and Python, though I'm equally comfortable on the full-stack side.
Outside of work I'm usually on a trail. I hike around the Carolinas regularly and try to get to new state parks whenever I can. I read a lot, mostly Sci-Fi, history, and philosophical fiction. Dostoevsky is a personal favorite, but my shelf ranges from Roman history to Harry Potter and The Boys in the Boat. I'm also a competitive gamer and put in real work to reach the upper tier of the CS2 ranked ladder in North America.

Completed: Operating Systems Principles, Software Engineering, Cloud Computing Technology, Artificial Intelligence, Automated Learning & Data Analysis, Computer & Network Security
In Progress: Architecture of Parallel Computers, Computer Networks, Internet Protocols
Highlights: Dean's List · NCSU Hackathon participant (NCSUHealth)
Coursework: Data Structures & Algorithms, Software Engineering, Operating Systems, Artificial Intelligence, Machine Learning & Data Analysis, Computer Security, Software Testing, Capstone Design
- Built an internal data observability library in Python and PySpark to aggregate, profile, compare, and reformat large datasets incrementally with profile and drift metrics.
- Reduced ingestion and reformatting time from 10 minutes to 10 seconds by optimizing profiling workflows and data transformations.
- Implemented SCD Type 2 pipelines with Delta Lake, PySpark, and SQL to preserve historical dimensional data across millions of records.
- Rebuilt the company website from WordPress/Elementor into a React static stack, achieving GTmetrix Grade A with 99% performance and 98% structure scores.
- Reduced payload to 100 KB and network requests to 5, improving page load consistency across all devices.
- Maintained and enhanced frontend/backend integrations supporting Beesbridge's Databricks delivery and AI/ML service offerings.

A selection of projects — see GitHub for more.
- SAS-sponsored senior design project (team of 5): built a governed catalog for enterprise data assets with 5+ blueprint templates for standardizing data products.
- Metadata-driven identification workflow over 5,000+ entries — 90% auto-suggestion accuracy, 80% reduction in manual curation time.
- Full-stack system with role-based access, schema-enforced metadata forms, and auditable review pipeline.
React · Django · PostgreSQL · Docker
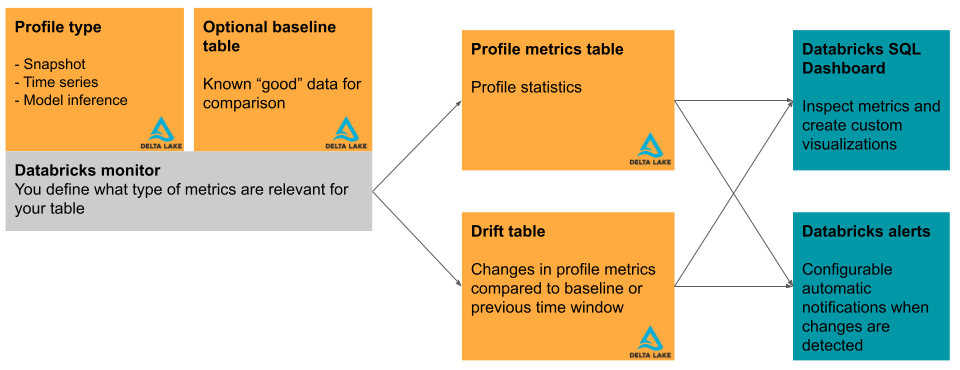
- Python/PySpark observability library tracking 15+ statistical metrics per column including drift detection across large datasets.
- Reduced ingestion and reformatting time from 10 minutes to 10 seconds (60× speedup) via optimized incremental transformations.
- Produced dashboard-ready outputs for downstream anomaly detection and reliability monitoring.
Python · PySpark · Delta Lake · Databricks
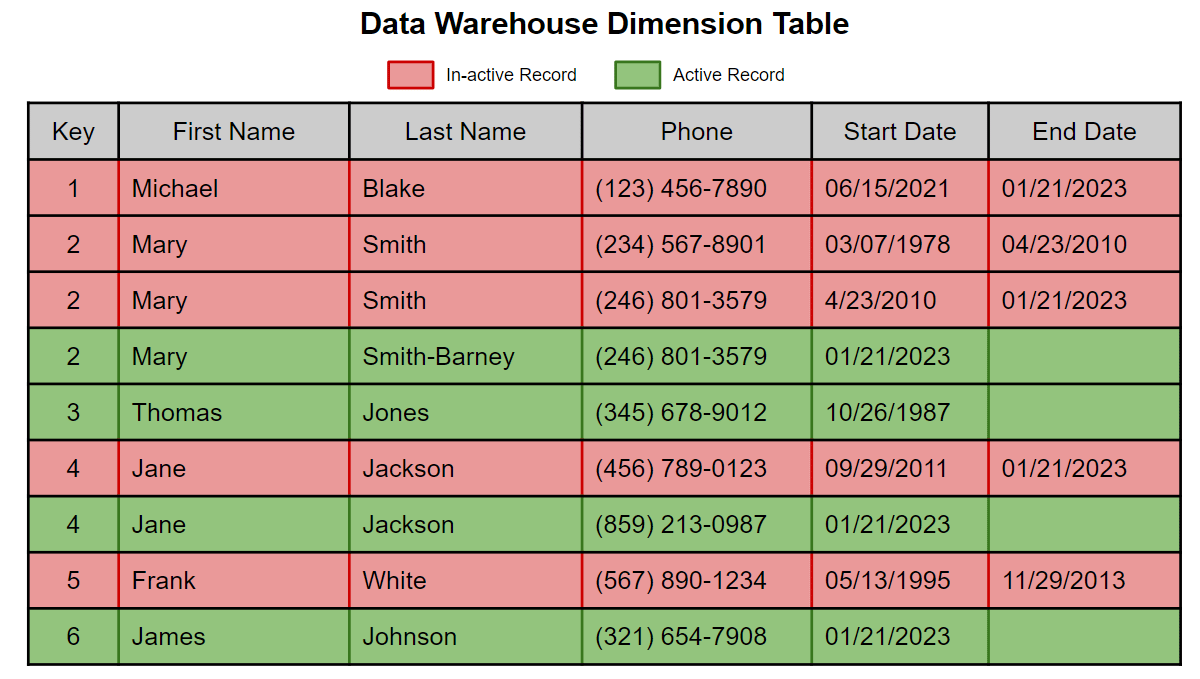
- SCD Type 2 patterns with Delta Lake, SQL, and PySpark preserving full historical dimensional data across millions of records.
- Auditable versioned records with effective date tracking for analytics, BI reporting, and compliance workflows.
PySpark · Delta Lake · SQL · Databricks

- Rebuilt from WordPress/Elementor into a React static stack — GTmetrix Grade A, 99% performance, 98% structure.
- Cut payload to 100 KB and network requests to 5; supports 150+ client case studies and enterprise service offerings.
React · HTML/CSS · JavaScript
- Full-stack health platform built at the NCSU Hackathon for nutrition and exercise tracking, integrating React, Django, and MongoDB.
- Designed scalable data pipelines and schema architecture for health-metric storage and efficient querying.
React · Django · MongoDB

- Feature-engineering pipeline transforming 6.59M EcoNET QA rows into model-ready tables by joining flagged observations with station history and metadata.
- Engineered lag, rolling-window, deviation, cyclic-calendar, and QA-summary features; evaluated Logistic Regression, Decision Tree, Random Forest, and HistGradientBoosting with time-aware splits.
- Best validation F1 of 0.869 and PR-AUC of 0.913 on the engineered feature set.
Python · Pandas · NumPy · scikit-learn · Matplotlib
- Analyzed a Kaggle dataset spanning 50+ attributes across Generations 1–8 to predict Pokémon battle strength using data mining techniques.
- Built neural network and decision tree models achieving 86% test accuracy and 91.74% overall accuracy respectively.
Python · Pandas · NumPy · PyTorch · scikit-learn · Matplotlib
- P1: XINU kernel bring-up and debug workflow with QEMU/GDB.
- P2: Starvation-aware schedulers implementing exponential and Linux-like scheduling policies.
- P3: Demand paging with virtual memory mapping and page-replacement instrumentation.
- P4: Unix file-system defragmenter in C over raw disk images and block metadata.
C · XINU OS · QEMU · GDB
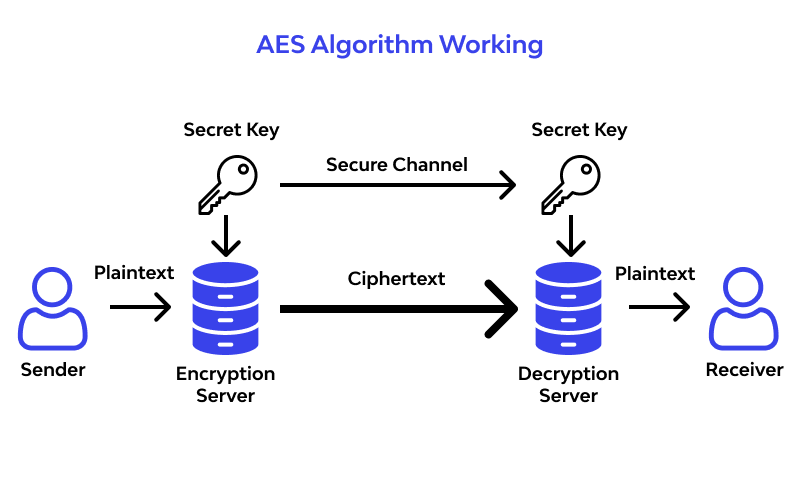
- Implemented AES-based encryption and decryption from scratch in C with build automation through Make.
C · Make
- Full-stack AI meal recommendation platform with authenticated REST APIs, MySQL-backed user profiles, and role-based access flows.
- Integrated an Ollama-powered local LLM generating personalized meal suggestions from user preference inputs and conversational context.
React · Spring Boot · MySQL · JWT · Ollama